

La relevancia semántica se podría considerar uno de los factores clave tanto en la clasificación de resultados en buscadores como en la selección de fuente de referencia por los LLMs, entre otros factores que no vamos a comentar aquí (autoridad, confiabilidad, etc.)
¿Qué es la relevancia semántica?
La relevancia semántica mide qué tan bien se relaciona el contenido de una página con la intención y el significado de una consulta (query), más allá de las coincidencias exactas de texto.
Por ejemplo, si alguien busca “cómo preparar café sin cafetera”, una página que hable de “métodos caseros para hacer café con filtro o prensa francesa” puede ser considerada muy relevante, aunque no repita exactamente las palabras de la consulta.
Factores principales de la relevancia semántica:
- Coincidencia de intención (Intent Matching): ¿El contenido responde directamente a la pregunta o necesidad del usuario?
- Cobertura temática (Topic Coverage): ¿Incluye todos los aspectos importantes del tema? (Aquí entra el juego el famoso query fan-out)
- Contexto semántico (Semantic Similarity): Uso de embeddings y modelos de lenguaje para medir similitud conceptual, no solo palabras clave.
- Actualidad (Freshness): Preferencia por contenido reciente si la consulta es sensible al tiempo (ej. noticias, tendencias). El famoso QDF (Query Deserves Freshness)
- Formato adecuado: Si el usuario busca una guía, se priorizan tutoriales; si busca datos, se priorizan informes.
Embeddings y contexto semántico
Para entender la relación entre dos textos (una página y una consulta), los buscadores y modelos de lenguaje (LLM) utilizan representaciones numéricas llamadas embeddings.
Un embedding transforma palabras, frases o documentos completos en vectores (listas de números) que capturan su significado semántico.
Así, dos textos con significados parecidos estarán cerca entre sí en ese espacio numérico.
Por ejemplo:
- “coche eléctrico” y “vehículo a batería” tendrán vectores muy similares.
- En cambio, “coche eléctrico” y “receta de pasta” estarán muy lejos.
Cómo se calcula la relevancia semántica a partir de los embeddings
Una vez que se tienen los embeddings tanto de la consulta (query) como del contenido de la página, se puede medir su similitud mediante una métrica matemática, como la similaridad del coseno.
Este cálculo devuelve una puntuación (o scoring) que refleja qué tan alineado está el significado de ambos textos. Cuanto mayor sea el valor, mayor será la relevancia semántica.
¡Ojo! Como hemos comentado antes, en la relevancia semántica entran en juego también otros factores.
Script de Python para analizar la relevancia semántica a través de embbedings
Ahora viene lo chulo.
Imagina que tienes varios artículos (URLs) y quieres saber cuál es más relevante para las querys que tienes en mente (tu URL vs la competencia). Este script hace exactamente eso, pero de forma automática y gratuita, sin necesidad de tirar de APIs con coste (como la de OpenAI o Google).
Link al script de Python en Google Colab (tendrás que hacerte una copia)
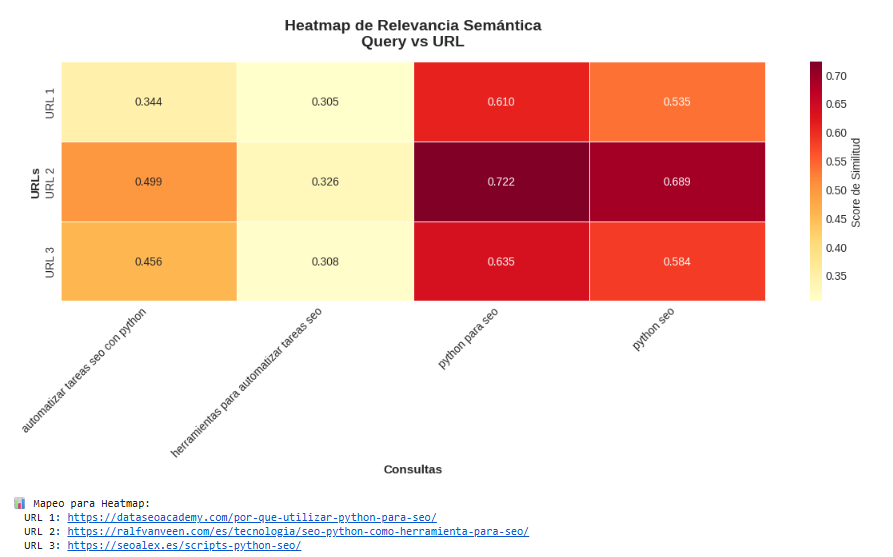
Visualizaciones que genera
- Gráficos de barras: Muestran el score de cada URL por query
- Heatmap: Compara todas las queries con todas las URLs en una matriz de colores
- Tabla: Lista ordenada con scores exactos
Componentes del script
Trafilatura
Función: Extraer contenido limpio de páginas web
Como: Un «limpiador» que quita todo lo innecesario
SentenceTransformers
Función: Convertir texto en embeddings
Modelo usado: paraphrase-multilingual-MiniLM-L12-v2 (puedes cambiar el modelo)
Ventaja: Entiende español, inglés y otros idiomas
Similitud Coseno
Función: Medir qué tan parecidos son dos vectores (embeddings)
Fórmula simplificada: Calcula el ángulo entre dos vectores
Ángulo pequeño = Muy similares
Ángulo grande = Muy diferentes
Otras opciones
Podrías utilizas Screaming Frog junto a la API de OpenAI para extraer los embeddings. La propia herramienta ya te permite calcular la relevancia semántica de los embeddings con respecto a una consulta, pero tiene un coste y la opción del script es totalmente gratis 😉
¿Cómo podemos mejorar la relevancia semántica para SEO?
Para mejorar la relevancia semántica de tus documentos para optimizar su posicionamiento en buscadores (SEO) y visibilidad en asistentes de Inteligencia Artificial puedes:
- Enriquecer el contenido con términos relacionados y sinónimos
Usa sinónimos y variaciones semánticas de los términos clave (ej. “optimización semántica” junto con “mejora del contexto”).
Incluye entidades relacionadas (personas, lugares, tecnologías) que suelen aparecer en consultas sobre el tema. - Incorporar preguntas y respuestas naturales
Añade secciones tipo FAQ con preguntas reales que los usuarios podrían hacer.
Ejemplo: Si la consulta es “cómo mejorar relevancia semántica”, incluye preguntas como: “¿Qué es relevancia semántica en SEO?”
“¿Cómo afecta la intención del usuario al ranking?” - Estructurar el contenido para claridad semántica
Usa encabezados jerárquicos (H1, H2, H3) que reflejen conceptos clave y subtemas.
Añade listas y tablas para organizar información, lo que ayuda a los modelos a entender relaciones. - Contextualizar con ejemplos y casos prácticos
Explica conceptos con ejemplos concretos relacionados con la consulta.
Esto aumenta la densidad semántica y la relevancia percibida por modelos de lenguaje. - Optimizar metadatos y marcado semántico
Title y meta description deben reflejar la intención principal.
Usa schema.org (marcado estructurado) para indicar tipo de contenido (artículo, tutorial, FAQ). - Actualidad y referencias
Incluye fechas de actualización y menciona fuentes recientes.
Esto refuerza la percepción de frescura, especialmente en temas dinámicos. - Lenguaje natural y coherencia
Evita keyword stuffing. Prioriza frases naturales que respondan a la intención.
Usa conectores y contexto para que el texto fluya como una respuesta humana.
Sobre el autor

Especialista SEO con gran foco en el área técnica. Entusiasta de la programación, en especial Python y Javascript, y la aplicación de ésta en el ámbito SEO para automatizar procesos o profundizar en ciertos ámbitos como el web scraping o el uso de APIs. He trabajado en proyectos SEO de muy diferente tamaño y sector lo que me permite obtener una perspectiva 360º de cómo trabajarlo.