
La indexación es el requisito esencial para asegurar la visibilidad orgánica de una web. Algunos buscadores en este sentido tienen un mejor desempeño que Google, con metodologías de indexación automática como el reciente protocolo IndexNow, de Yandex y Bing, que permite la indexación instantánea de cualquier contenido. En Google lo tenemos más complicado y aunque hay métodos para automatizar y potenciar el rastreo de nuestra web, la indexación no se asegura en este buscador.
Hoy quería mostraros una metodología para analizar la indexación y obtener un approach de ‘cuanto de bien’ está indexada nuestra web en Google. Ya existen métodos directos a los que acudir para cerciorarnos si nuestra web está indexada o no, como la reciente API de inspección de URLs con la que podemos hacer unas 2.000 llamadas diarias y conocer si las URLs están en Google o no, entre otras cosas. Sin embargo, quería conseguir algo rápido que me permitiera obtener una visión aproximada de si existen o no problemas de indexación que requieran un enfoque posterior más detallado y preciso, como por ejemplo, con el uso de la API.
La metodología que he seguido se basa en el comando "site"* para conocer el volúmen de URLs indexadas en Google. La idea es hacer un comando site en bulk para todos los directorios de una web y conocer aproximadamente el volúmen de URLs indexadas en cada directorio. Estos valores los analizamos en conjunto con el número de URLs totales y el número de URLs index de cada directorio en base a un rastreo previo con Screaming Frog. *site:https://www.dominio.com/directorio
Os he dejado el script con detalles del proceso en Google Colaboratory, para quien quiera trastearlo y adaptarlo a su propio proyecto.
Ahora vayamos al grano explicando el proceso.
Explicación y funcionamiento del script
Librerías utilizadas
Vamos a utilizar 3 librerías en concreto:
!pip install ecommercetools
!pip install matplotlib
!pip install pandas import matplotlib.pyplot as plt
from ecommercetools import seo
import pandas as pdComo he comentado, la idea es hacer en bulk un comando site para todos los directorios de una web y extraer el número de resultados que arroja Google. Hacerlo manualmente puede ser tedioso y para eso tenemos la magia de Python. Una vez tengamos estos datos, los uniremos al número de URLs totales que tiene cada directorio y al número de URLs con la directiva index en base a un rastreo previo de Screaming Frog.
Por tanto, vamos a jugar con tres métricas:
- URLs totales: Número de URLs contenidas en cada directorio (html, imágenes, pdf, etc.)
- URLs index: Número de URLs con la directiva index. Esto acota el número de URLs a aquellos documentos HTML que son indexables, o en otras palabras, las URLs que deberían estar en Google indexadas.
- URLs indexadas: Número de URLs del directorio que están presentes en Google. Este dato se extrae del comando «site» y realmente es aproximado al número real.
Paso 1: Extracción de URLs totales y URLs index de cada directorio
El análisis de ejemplo lo voy a hacer con la tienda online menzzo.es.
Lo primero que tenemos que hacer es un rastreo de la web.
En la pestaña de «Site Structure», exportamos el nivel 2 de URLs, del cual vamos a obtener el número total de URLs de cada directorio:
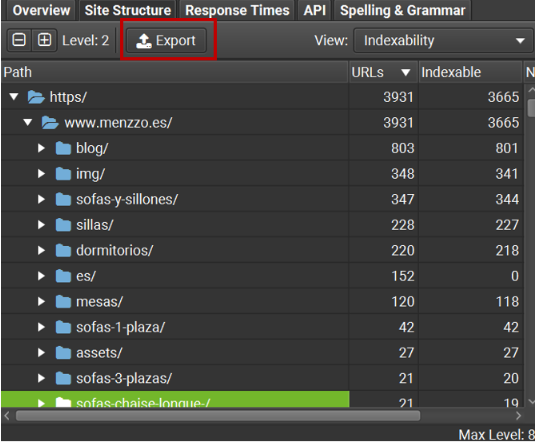
En este Excel tenemos que dejar solo los directorios para los que queremos hacer el análisis y tiene que tener el siguiente formato:

Leemos el excel y nos quedamos solamente con las dos primeras columnas almacenados en un Dataframe de Pandas:
df_urls = pd.read_excel('indexability.xlsx')
df_urls.drop(['Indexable', 'Non-Indexable'], inplace=True, axis=1)Ahora volvemos a Screaming Frog y vamos a la pestaña «Directives» > «Index» > Formato árbol y exportamos el excel con los resultados. Como hemos dicho, de aquí extraemos el nº de URLs de cada directorio que tienen la metaetiqueta robots «index», y por tanto, que deberían estar en Google.
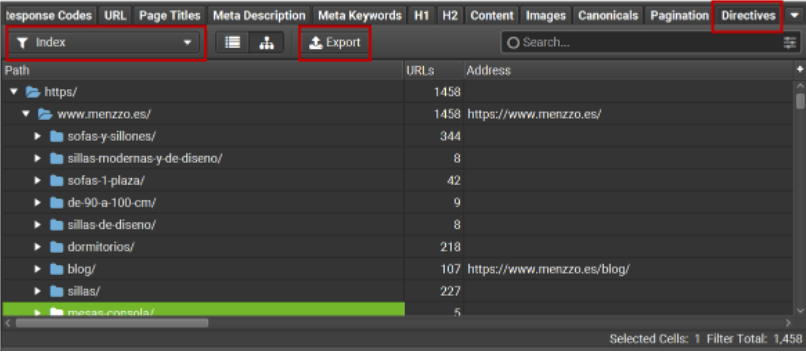
El formato del excel tiene que quedar así (la primera columna debe llamarse «Directorios»):
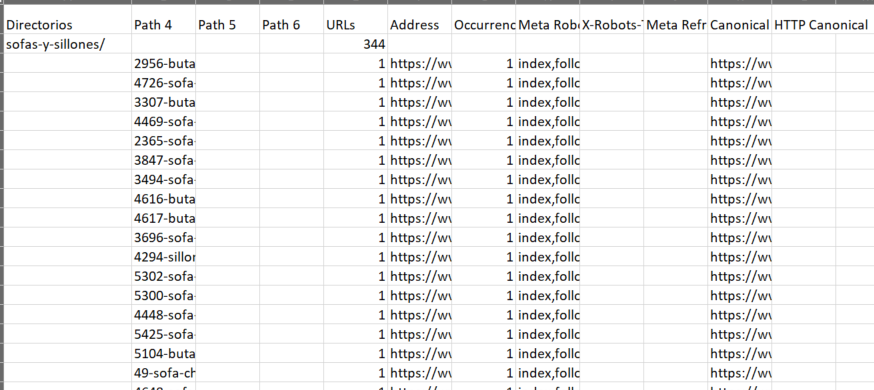
Ahora leemos este nuevo excel y lo mergeamos con el primero, quedandonos solamente con las columnas que nos interesan (Directorios, URLs totales y URLs index) en un nuevo dataframe:
df_index = pd.read_excel('directives_index.xlsx')
df_mg = df_index.merge(df_urls, how='right', left_on='Directorios', right_on='Directorios' )
df_mg2 = df_mg.drop(df_mg.columns.difference(['URLs_x','URLs_y', 'Directorios']), 1)
df_mg2 = df_mg2.dropna()
df_mg2.rename(columns={'URLs_x': 'URLs Index', 'URLs_y': 'URLs totales' }, inplace=True)
urls_index = df_mg2['URLs Index'].tolist()
urls_index = [int(x) for x in urls_index]
df_mg2['URLs Index'] = urls_indexPaso 2: Extraer en bulk las URLs indexadas de cada directorio
Ahora es cuando vamos a hacer uso de un método que tiene la clase seo de ecommercetools, que es get_indexed_pages() y al que le podemos pasar un listado de URLs para obtener el número de URLs indexadas.
Para ello, leemos el conjunto de directorios de nuestro dataframe anterior y se lo pasamos al método mencionado.
El resultado se almacena en un nuevo dataframe:
direct = df_mg2['Directorios'].tolist()
direct = ['https://www.menzzo.es/'+x for x in direct]
df2 = seo.get_indexed_pages(direct)
n_pages = df2['indexed_pages'].tolist()
n_pages = [int(x) for x in n_pages]
clean_urls = df2['url'].tolist()
clean_urls = [url.replace('https://www.menzzo.es/', '') for url in clean_urls]
df2['url'] = clean_urls
df2.rename(columns={'url': 'Directorios'}, inplace=True)Paso 3: Mergeamos los Dataframes y pintamos el gráfico de barras
Por último, mergeamos los dataframes anteriores y pintamos los gráficos de barras, gracias al cual podremos hacer un estudio del estado de indexación cada directorio:
df_merge = df2.merge(df_mg2, how='left', left_on='Directorios', right_on='Directorios')
df_merge.rename(columns={'indexed_pages': 'URLs indexadas'}, inplace=True)
df_merge.set_index('Directorios', inplace=True)
ax = df_merge.astype(float).plot.bar(rot=45, figsize=(28,10), color=['yellow', 'black', 'red'], width=0.8)
for p in ax.patches:
ax.annotate(format(p.get_height()),
(p.get_x() + p.get_width() / 2,
p.get_height()), ha='center', va='center',
size=12, xytext=(0, 8),
textcoords='offset points')
plt.grid(linewidth = 0.2)
plt.xticks(fontsize=18)
plt.xlabel('Directorios', fontsize=18)
plt.legend(fontsize=18)
plt.show()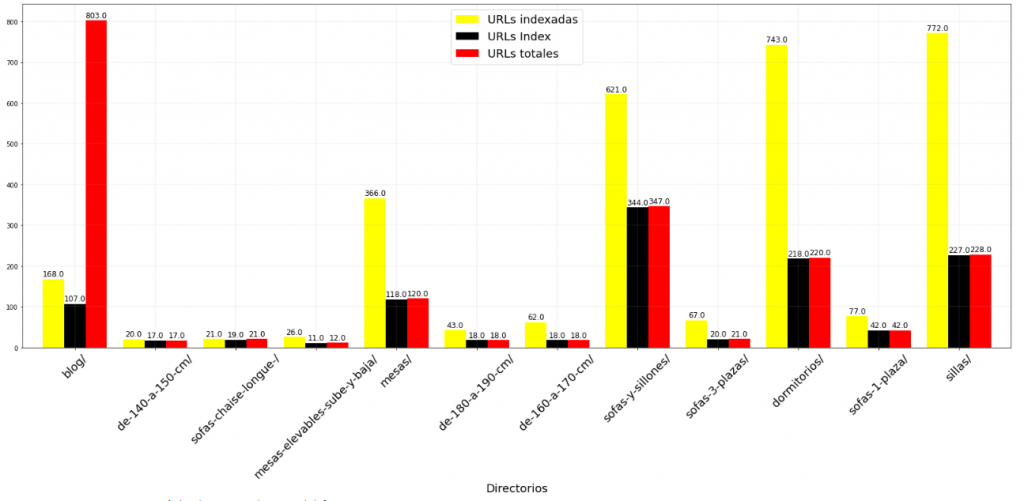
Conclusión
De este análisis podríamos sacar algún insight valioso que nos puede llevar a analizar de forma más detallada la indexación, como puede ser:
- Menos URLs indexadas de las que debería. Puede haber algún problema de indexación si existen muchas menos URLs indexadas con respecto al total de URLs y de URLs con la directiva index.
- Más URLs indexadas de las que debería. En caso contrario, puede que se esté indexando «morralla» que no nos interesa y para la que deberíamos estudiar a fondo una posible solución.
Sobre el autor

Especialista SEO con gran foco en el área técnica. Entusiasta de la programación, en especial Python y Javascript, y la aplicación de ésta en el ámbito SEO para automatizar procesos o profundizar en ciertos ámbitos como el web scraping o el uso de APIs. He trabajado en proyectos SEO de muy diferente tamaño y sector lo que me permite obtener una perspectiva 360º de cómo trabajarlo.