
Video resumen del artículo
Señales ABC de Google
Antes de hablar de Navboost, hay que entender algunos conceptos relacionados sobre el sistema de ranking de Google. Las señales ABC (Anchors, Body y Clicks) hacen referencia a como los propios ingenieros de Google agrupan sus señales internas según los documentos del juicio antimonopolio en EE. UU. y las deposiciones de Pandu Nayak y HJ Kim.
En resumen rápido (y luego lo desgranamos):
- A – Anchors: qué dicen de ti los enlaces que apuntan a tu página.
- B – Body: qué dices tú mismo en el contenido de la página.
- C – Clicks: qué hacen los usuarios cuando se encuentran tu resultado en Google.
Estas tres cosas se combinan para calcular T* (“Topicality”), que es la puntuación de relevancia temática de un documento respecto a una consulta. Es decir, lo primero que Google mira para decidir si tu página va de lo que el usuario está buscando.
Y ojo al contexto: en los documentos del caso del DOJ se ve que Google agrupa sus señales en grandes “buckets”:
- ABC → Topicalidad (T*)
- Navboost → comportamiento de clics por consulta/documento
- Quality / Q* → calidad/autoridad relativamente estática de la página o del sitio
Traducido: primero decide si tu página es afín con la búsqueda del usuario (ABC/T*), luego ajusta con lo que la gente hace en los resultados (Navboost) y con qué tan fiable pareces (Q*). Navboost vive en el “C” de ese ABC, pero eso lo destripamos después.
A de Anchors: lo que otros dicen de ti
Anchors son, básicamente, los textos de enlace que apuntan a una URL: tanto internos como externos.
Google usa esos anchors para inferir de qué va tu página: si diez webs fiables te enlazan con algo tipo “guía de Navboost para SEOs”, el buscador empieza a sospechar que quizá tu página… va de Navboost para SEOs. A nivel práctico:
Enlaces externos con anchors descriptivos refuerzan el tema principal de la página. Los enlaces internos también pesan: ayudan a Google a entender la arquitectura temática de tu sitio. Anchors genéricos tipo “haz clic aquí” aportan cero contexto.
Cuando este etiquetado encaja con la intención de búsqueda de una query, tu T* sube.
B de Body: lo que realmente hay en tu página
El Body es el contenido en sí: el texto que vive en la página, con sus términos, contexto semántico, estructura, etc. Google no se queda en contar keywords: analiza la coherencia semántica y cómo el contenido responde a la intención de la query.
C de Clicks: lo que hacen los usuarios contigo
Y llegamos al punto divertido: Clicks.
El “C” de ABC es cómo Google mide lo que hacen los usuarios con tu resultado: si te clican, cuánto rato se quedan, si vuelven corriendo al buscador (pogo-sticking), etc. En los documentos y análisis públicos se habla específicamente de cosas como tiempo de permanencia antes de volver a la SERP y otros patrones de interacción. Vamos a analizarlo en profundidad
Navboost es, dicho mal y pronto, el sistema de Google que convierte los clics de la gente en poder de ranking. Es el sistema interno de Google que mira qué resultados la gente elige, cuánto interactúa con ellos y, a partir de ahí, empuja esos documentos hacia arriba o hacia abajo en las SERPs. A nivel interno, Navboost forma parte de los sistemas que alimentan la popularidad / comportamiento de usuario dentro del ranking, junto con cosas como Topicality (T*) y Q*.
Lo que sabemos hoy, gracias al juicio antimonopolio del DOJ y a documentación filtrada, se puede resumir así:
Navboost es un sistema de ranking de Google basado en señales de interacción de usuario: clics, tiempo hasta volver a la SERP, patrones de engagement, etc.
Guarda el histórico de comportamiento: unos 13 meses de datos de clics por consulta/URL; antes de 2017 eran 18 meses, y separa datos por dispositivo (móvil/desktop) y por localización, de modo que no mezclas el comportamiento de un usuario móvil en México con uno de escritorio en Alemania. En el juicio, Google llega a describir Navboost, básicamente, como una “gran tabla” de datos agregados de interacción de usuario, más que como un modelo mágico de machine learning estilo película de ciencia ficción.
Navboost entra con el histórico de comportamiento:
- para la query X,
- en el país Y,
- en el dispositivo Z,
¿Qué URLs se han comportado como good clicks de forma consistente durante meses?
Esa capa de “memoria de clics” es la que hace que, aunque publiques “el mejor contenido del mundo” para una búsqueda concreta, Google no te relegue en las mejores posiciones si los usuarios no te validan con sus acciones.
Aquí viene la parte curiosa: Navboost no es nuevo, lleva ahí desde mediados de los 2000. Distintas fuentes que analizan el testimonio de Pandu Nayak apuntan a que Navboost empezó alrededor de 2005, incluso “2005 o antes”. Uno de los primeros indicios públicos fue un documento judicial de 2012 filtrado y publicado por el Wall Street Journal, donde Udi Manber (entonces en Google) admite que los clics influyen en los rankings. Mientras tanto, en el mundillo SEO, gente como Rand Fishkin llevaba años haciendo experimentos de “clic masivo coordinado” y demostrando que el comportamiento de usuario podía mover rankings… mientras portavoces de Google lo negaban una y otra vez en foros, conferencias y redes sociales.
Así que la cronología real es algo como:
- ~2005 → Google empieza a usar Navboost internamente para explotar datos de clics.
- 2010–2012 → primeras pistas en documentos y declaraciones legales de que los clics importan.
- 2013–2020 → la comunidad SEO sospecha, prueba, publica experimentos; Google lo niega públicamente.
- 2023–2025 → juicio antimonopolio DOJ + filtraciones del Content Warehouse sacan el nombre Navboost a la luz y confirman que no estábamos tan locos.
Clasificación de clics: bad clicks, good clicks y lastLongestClicks
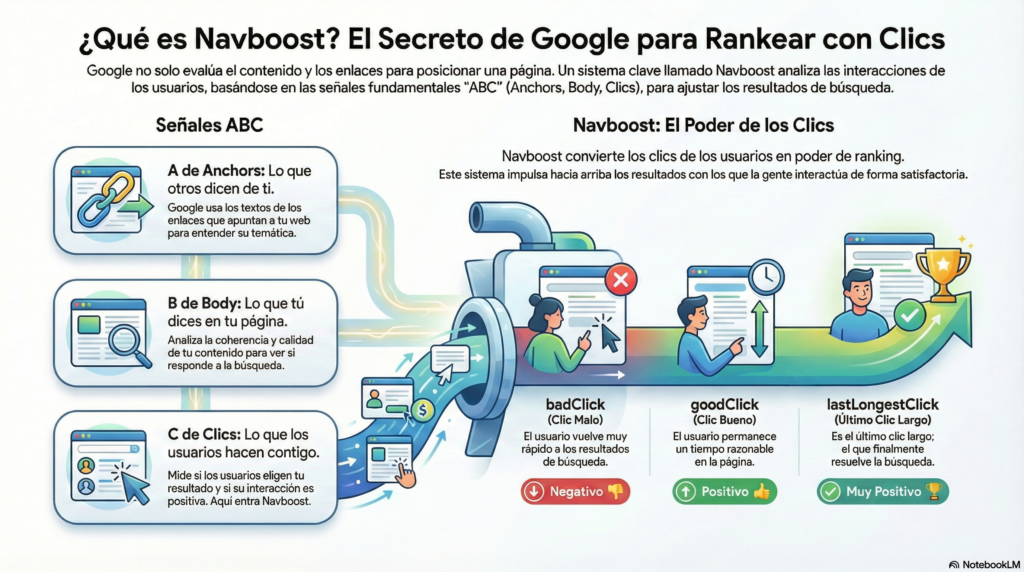
Para Google no todos los clics valen lo mismo, así que los clasifica y los cuenta de forma distinta usando métricas internas como badClicks, goodClicks, lastLongestClicks y unsquashedClicks según la documentación filtrada y el leak del Content Warehouse. Básicamente, clasifican los clics como:
- badClicks → clics que huelen a “me he arrepentido en menos de un suspiro”.
- goodClicks → clics donde el usuario parece más o menos feliz con lo que ha encontrado.
- lastLongestClicks → el último clic largo de la sesión, la página donde el usuario por fin se queda tranquilo y deja de buscar.
Vamos uno por uno.
badClicks: cuando el usuario sale corriendo
A partir del análisis de los docs filtrados, se consideran clics negativos cuando el usuario:
- vuelve muy rápido a la SERP,
- rebota casi instantáneamente,
- o muestra señales claras de insatisfacción (pogo-sticking de libro).
Ejemplos típicos de fábrica de badClicks:
- Titles y meta descriptions clickbait que prometen oro y entregan serrín.
- Contenido que no responde la intención (artículo de relleno cuando el usuario quería algo práctico, rápido o local).
- UX infernal: pop-ups, overlays, anuncios invasivos, diseño roto en móvil, etc.
Desde el punto de vista de Navboost, un exceso de badClicks es como ir acumulando informes negativos en tu expediente para esa búsqueda concreta.
goodClicks: cuando tu página “funciona”
Los goodClicks son «Clics donde el usuario entra, se queda un rato razonable, interactúa con el contenido y no parece salir escopetado hacia la SERP».
Google no mira tu Google Analytics (supuestamente), pero sí puede estimar:
- cuánto tardas en volver a la SERP,
- si cambias de resultado,
- si repites la query,
- o si sigues refinando porque no has quedado satisfecho.
Cuando esos patrones apuntan a “el usuario aquí ha encontrado algo útil”, ese clic entra en el saco de goodClicks.
lastLongestClicks: el clic que “cierra” la búsqueda
Y luego están los lastLongestClicks, que suenan a hechizo de Hogwarts pero son bastante lógicos. Es, simplificando, el último clic largo de la sesión de búsqueda; la página donde el usuario pasa más tiempo y después ya no vuelve a la SERP a seguir probando cosas. Distintos análisis de los docs y resúmenes de Navboost lo explican así:
query → clic 1 → vuelta → clic 2 → vuelta → clic 3…
De todos esos, identifica: el clic más largo (longest click). Ese lastLongestClick es, para Google, la mejor candidata a ser la página que realmente resolvió el problema. Ahora imagina eso no con 10 usuarios, sino con meses y meses de búsquedas para la query X, en el país Y y en dispositivo Z,
¿qué URLs aparecen una y otra vez como lastLongestClick en el histórico de 13 meses que usa Navboost?
Esas son las páginas que el sistema tiende a empujar hacia arriba, porque la evidencia dice que suelen ser las que cierran la búsqueda de forma satisfactoria.
Patente US8595225B1: Systems and methods for correlating document topicality and popularity
La joyita en cuestión es la patente US8595225B1, titulada: “Systems and methods for correlating document topicality and popularity”. Firmada por Amit Singhal y Urs Hölzle, dos pesos pesados históricos de Google Search. Traducido a idioma humano, lo que explican en la patente es:
“Vamos a juntar de qué va una página (su tema) con lo popular que es según lo que hace la gente, y con eso reordenamos los resultados.”
¿Te suena a Navboost? Normal. Muchos análisis apuntan a que esta patente es el plano conceptual del sistema.
¿Cual es la idea central de esta patente?
La patente intenta resolver un problema muy simple: “No basta con saber si una página es sobre un tema. También necesitamos saber si la gente realmente la elige y la usa para ese tema.”
Así que propone un sistema que:
- Escucha lo que hace el usuario (qué documentos visita).
- Agrupa esos documentos por tema.
- Cuenta lo populares que son dentro de cada tema.
- Usa esa info para subir o bajar resultados en el ranking.
Vamos a desmigajar la información que viene incluida en la patente sobre el funcionamiento teórico de Navboost:
Paso 1: Google mira qué documentos visita la gente
El sistema parte de algo muy básico: los documentos que los usuarios visitan. Cuando un usuario abre un documento (por ejemplo, una página web), el cliente envía al servidor un identificador de ubicación (la URL). Si esa visita viene de una búsqueda, también se manda la consulta que se usó y los resultados que se mostraron.
Es decir, el servidor va almacenando pares del tipo:
query → documentos visitados (URLs)
Este servidor se llama en la patente “topicality/popularity server” y vive al lado del buscador principal.
Paso 2: Mapear documentos y queries a “topics”
Luego viene la parte de temas (“topics”):
- Cada documento se puede asignar a uno o varios temas.
- Cada consulta también se puede asignar a uno o varios temas.
¿Y cómo se hace eso?
La patente menciona varias opciones, por ejemplo:
- Usar un directorio temático (rollo antiguo directorio de Google: si la página está en “Viajes”, la topic es “viajes”).
- Usar el contenido textual de los documentos devueltos para esa query y derivar de ahí el tema.
- Agrupar topics en jerarquías (subtemas y temas padre).
Resultado:
Google puede extraer información del tipo:
- Esta URL vive en “Viajes > Europa > Londres”
- Esta query también suele asociarse a “Viajes > Europa > Londres”
- Y esto es clave: la patente no habla sólo de “popularidad global”, sino de popularidad por tema.
Paso 3: Asignar un “popularity score” a cada documento
Aquí entra la parte que nos interesa como SEOs: cómo mide la “popularidad” la patente.
Popularidad = número de visitas: cuanto más se visita un documento, más alto su popularity score.
Pero luego se pone interesante, porque introduce las patrones de navegación. Habla de analizar cómo navega la gente hacia y desde un documento.
Menciona explícitamente casos como:
- Páginas que sólo están “canalizando” tráfico hacia otra (funnel pages) → quizás son menos valiosas.
- Usuarios que visitan una primera página, se quedan muy poco tiempo (ej. menos de 20 segundos) y saltan a otra → esa primera página puede ser de valor limitado.
Eso ya huele a:
- Clics rápidos + poco tiempo en el resultado = mala señal,
- Clics con permanencia + sin saltos extra = buena señal.
Todo muy alineado con lo que hoy llamamos bad clicks / good clicks / lastLongestClicks en Navboost, sólo que aquí lo envuelven en el término neutral “navigational patterns”.
Paso 4: Per-topic popularity (popularidad por tema)
Una vez que cada documento tiene uno o varios temas asignados, y un popularity score, el sistema correlaciona ambos mundos. Para cada topic, ordena los documentos por su popularidad; ese proceso genera lo que la patente llama “per-topic popularity”:
Dentro del tema “viajes”, se ordenan las páginas por popularidad y dentro del tema “finanzas personales”, lo mismo. Y así con cada topic y subtopic.
Paso 5: Usar esa info para reordenar los resultados
Y aquí la chicha: La patente dice que esta per-topic popularity se puede usar para crear puntuaciones de calidad específicas por tema y usarlas como señal de ranking en el buscador. Es decir, “boostear” un documento dentro de los resultados de una búsqueda usando el topic asociado a la query, y la popularidad del documento dentro de ese topic.
Incluso llega a hablar de combinar popularidad de documentos devueltos por una query para generar una popularidad específica por consulta.
Sobre el autor

Especialista SEO con gran foco en el área técnica. Entusiasta de la programación, en especial Python y Javascript, y la aplicación de ésta en el ámbito SEO para automatizar procesos o profundizar en ciertos ámbitos como el web scraping o el uso de APIs. He trabajado en proyectos SEO de muy diferente tamaño y sector lo que me permite obtener una perspectiva 360º de cómo trabajarlo.