
Como todos sabemos, Google permite ahora acceder a los datos del inspector de URL a través de la nueva API. Esto es una gran noticia para el sector puesto que podemos trabajar estos datos en bulk en lugar de ir una por una en la app de Search Console.
Los límites de uso no son gran cosa para proyectos grandes (unas 2.000 request/dia) pero nos puede hacer el apaño en proyectos medianos. Además, te contaré una trampilla que puedes hacer para saltarte este límite 😛
Vayamos paso por paso.
Disclaimer: Doy por hecho que tienes ciertos conocimientos en Python y estás medianamente familiarizado con la API de Google Search Console.
Consigue tus credenciales JSON en Google API Console
Primero tendríamos que crearnos un nuevo proyecto y configurar la correspondiente pantalla de consentimiento.
Este vídeo te puede ayudar con estos dos pasos:
Una vez tengamos nuestro proyecto creado, en el apartado de Credenciales tendrías que clickar en «Crear Credenciales» y seleccionar «Cuenta de servicio».
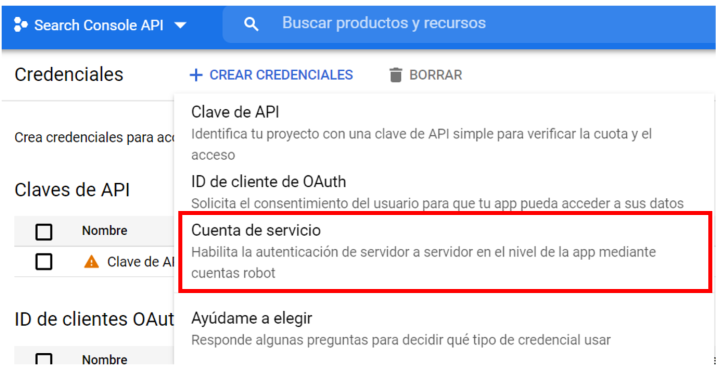
Una vez hagamos esto, rellenamos el formulario para obtener una cuenta de correo asociada a nuestra cuenta de servicio. Ponle un nombre sencillo, en mi caso:

Una vez tengamos esto ya creado, tenemos que obtener nuestro JSON de credenciales, que será el que almacenemos en el directorio donde vamos a trabajar con Python.
Accede a tu cuenta de servicio y ve al apartado «Claves»:
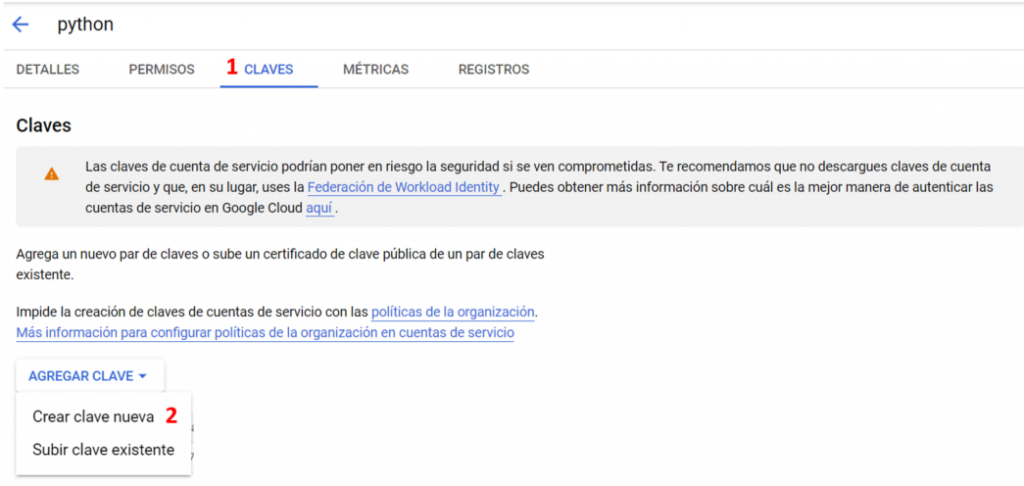
Por último clicka en la opción JSON, descarga tu fichero y nómbralo como «client_secrets.json».
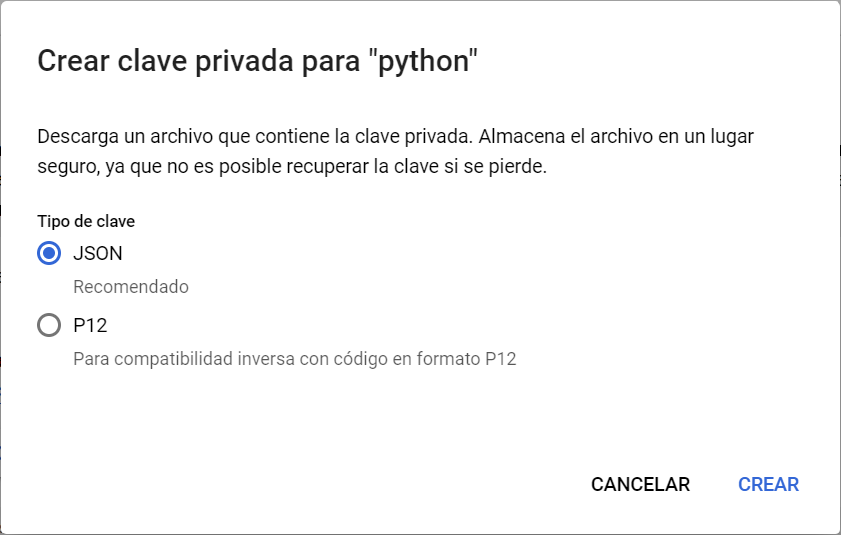
Más información para conseguir tus credenciales JSON con una cuenta de servicio.
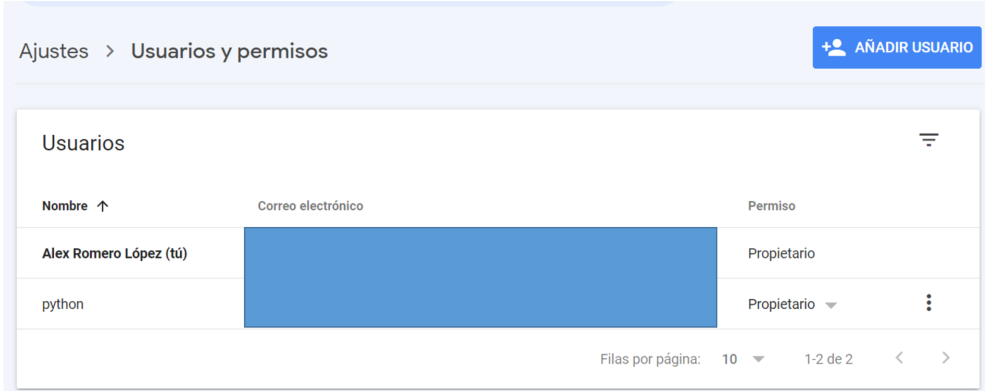
Agregar usuario en Google Search Console
Por último, tenemos que agregar este correo electrónico asociado a nuestra cuenta de servicio en nuestra propiedad de Google Search Console con permiso de Propietario.
Trabajar la URL Inspection API con Python
Una vez configurado todo el acceso a nuestra propiedad de Google Search Console, el código es bastante sencillo.
Lo que vamos a hacer es leer un fichero CSV donde estarán todas las URLs que queremos evaluar, crear un loop donde haremos las request y almacenar todos los datos en otro CSV a través de Pandas.
Por tanto, las librerías que vamos a usar son:
from google.oauth2 import service_account
from googleapiclient.discovery import build
import pandas as pd
from tqdm import tqdm
from dateutil.parser import parse´Después creamos nuestra función de acceso con las credenciales JSON que nos hemos guardado en la carpeta donde estamos trabajando:
# Connect GSC
key = "client_secrets.json"
def connect(key):
scope = ['https://www.googleapis.com/auth/webmasters']
credentials = service_account.Credentials.from_service_account_file(key, scopes=scope)
service = build('searchconsole','v1',credentials=credentials)
return service
service = connect(key)Ahora leemos nuestro CSV donde están todas las URLs que queremos analizar (<2000) y creamos un bucle para ir haciendo la request a la API y almacenar los resultados en listas que luego utilizaremos para crear nuestro DataFrame, y por último, nuestro CSV.
# Read CSV and Request to API
csv_urls = open('urls.csv', 'r')
urls = [url.strip() for url in csv_urls]
verdict = []
coverageState = []
robotsTxtState = []
indexingState= []
sitemap = []
pageFetchState = []
lastCrawlTime = []
for url in tqdm(urls):
request = {
"inspectionUrl": url,
"languageCode": "es-ES",
"siteUrl": "sc-domain:seoalex.es"
}
try:
response = service.urlInspection().index().inspect(body=request).execute()
#valores
inspectionResult = response['inspectionResult']
verdict.append(inspectionResult['indexStatusResult']['verdict'])
coverageState.append(inspectionResult['indexStatusResult']['coverageState'])
robotsTxtState.append(inspectionResult['indexStatusResult']['robotsTxtState'])
indexingState.append(inspectionResult['indexStatusResult']['indexingState'])
pageFetchState.append(inspectionResult['indexStatusResult']['pageFetchState'])
if 'sitemap' in inspectionResult['indexStatusResult']:
sitemap.append(inspectionResult['indexStatusResult']['sitemap'])
else:
sitemap.append("N/A")
if 'lastCrawlTime' in inspectionResult['indexStatusResult']:
time = parse(inspectionResult['indexStatusResult']['lastCrawlTime'])
lastCrawlTime.append(time.date())
else:
lastCrawlTime.append("Never")
except:
verdict.append('ERROR')
coverageState.append('ERROR')
robotsTxtState.append('ERROR')
indexingState.append('ERROR')
pageFetchState.append('ERROR')
sitemap.append('ERROR')
lastCrawlTime.append('ERROR')
df = pd.DataFrame({
'URL': urls,
'Status': verdict,
'Estado de indexación': indexingState,
'Status de cobertura': coverageState,
'Robots.txt status': robotsTxtState,
'PageFetch Status': pageFetchState,
'¿En sitemap?': sitemap,
'Último rastreo': lastCrawlTime
})
df.to_csv('Outputs/batch1_status.csv',encoding='utf-8')Y con esto ya tendríamos nuestro fichero final y el status de todas las URLs:
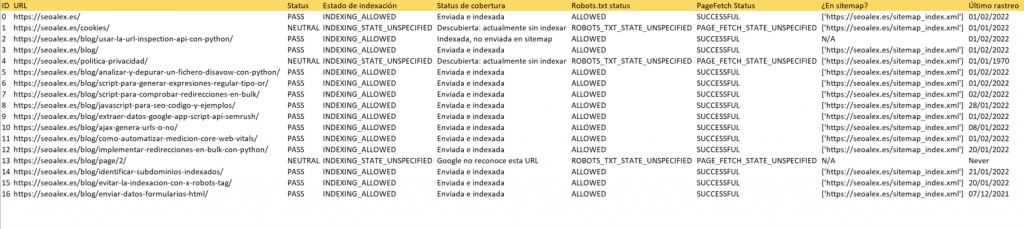
«Saltarse» los límites de uso para un mismo dominio
Como «truqui» final, he leído que los límites son a nivel de propiedad, por lo que podríamos dar de alta varias propiedades en nuestro Search Console, por ejemplo, con directorios diferentes, e ir haciendo 2.000 request por propiedad. Con esto incrementamos mucho el nº de peticiones que podemos hacer a cada sección de nuestra web. Esto tengo que probarlo aún pero me parece sencillo.
Aquí la info:
Aaaaand there’s the way to get around the 2k per day URL inspection limit for the new GSC API.
— Lily Ray 😏 (@lilyraynyc) January 31, 2022
Brilliant question @suzukik https://t.co/JkM3Xzzprd
Sobre el autor

Especialista SEO con gran foco en el área técnica. Entusiasta de la programación, en especial Python y Javascript, y la aplicación de ésta en el ámbito SEO para automatizar procesos o profundizar en ciertos ámbitos como el web scraping o el uso de APIs. He trabajado en proyectos SEO de muy diferente tamaño y sector lo que me permite obtener una perspectiva 360º de cómo trabajarlo.